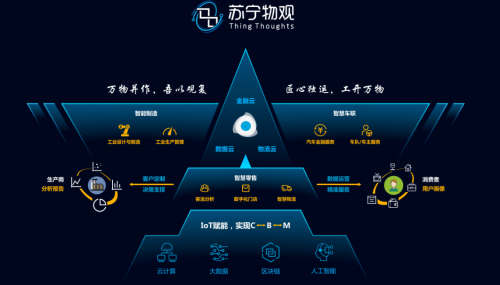
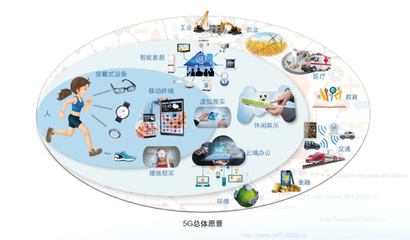
隨著工業互聯網的快速發展,數據已成為驅動制造業數字化轉型的關鍵要素。而邊緣計算作為新興的計算模式,正日益成為工業互聯網不可或缺的技術支撐。本文將從邊緣計算的定義、工業互聯網數據服務的需求以及兩者的深度融合等方面展開探討。
一、邊緣計算的定義與特點
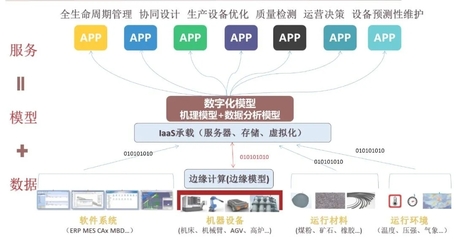
邊緣計算是一種分布式計算架構,將數據處理和分析任務從云端下沉到網絡邊緣,即靠近數據源頭的設備或網關。其核心特點包括低延遲、高帶寬利用、數據本地化處理以及增強的隱私保護。在工業場景中,邊緣計算能夠實時響應設備數據,減少云端傳輸負擔,提升系統可靠性。
二、工業互聯網數據服務的挑戰與需求
工業互聯網通過連接設備、傳感器和控制系統,生成海量實時數據。這些數據服務面臨多重挑戰:工業設備產生的數據量巨大,若全部上傳至云端,將導致網絡擁堵和延遲問題;許多工業應用(如智能制造、預測性維護)要求毫秒級的響應時間,云端處理難以滿足;數據安全和隱私保護在工業環境中尤為重要。因此,工業互聯網亟需一種高效、可靠的數據處理方案。
三、邊緣計算在工業互聯網數據服務中的關鍵作用
邊緣計算通過本地化數據處理,完美契合工業互聯網的需求。具體體現在:
- 實時性提升:在邊緣節點進行數據預處理和分析,能夠實現毫秒級響應,支持實時監控和控制系統。例如,在智能制造中,邊緣計算可以即時調整生產線參數,避免停機損失。
- 帶寬優化:通過過濾和壓縮數據,邊緣計算減少向云端傳輸的數據量,降低網絡成本,并提高整體系統效率。
- 數據安全與隱私:敏感數據可在本地處理,避免在傳輸過程中被竊取,符合工業數據保護法規。
- 可靠性增強:即使在網絡中斷的情況下,邊緣設備也能獨立運行,確保關鍵工業流程的連續性。
四、實際應用案例與未來展望
在工業互聯網領域,邊緣計算已廣泛應用于預測性維護、質量控制、能源管理等場景。例如,一家制造企業通過部署邊緣計算節點,實時分析設備傳感器數據,提前預測故障,減少維修時間達30%。未來,隨著5G和人工智能技術的發展,邊緣計算將與云計算協同,構建更加智能、自適應的工業互聯網生態系統。
邊緣計算不僅是工業互聯網數據服務的技術基石,更是推動制造業智能化轉型的關鍵驅動力。企業應積極擁抱這一趨勢,優化數據架構,以提升競爭力和創新力。